Com os avanços da IA Generativa, ficou muito mais simples tirar sistemas de IA do papel. Porém, essa simplicidade esconde algumas armadilhas. Neste artigo, compartilho aprendizados e boas práticas para montar agentes confiáveis de forma ágil.
Agentes
De acordo com a definição em “Artificial Intelligence: A Modern Approach”1, Inteligência Artificial é o estudo de agentes racionais. Simplificando, são sistemas que “tentam fazer a coisa certa” segundo algum objetivo. Eles podem perceber um ambiente (utilizando sensores) e agir sobre ele (com atuadores).
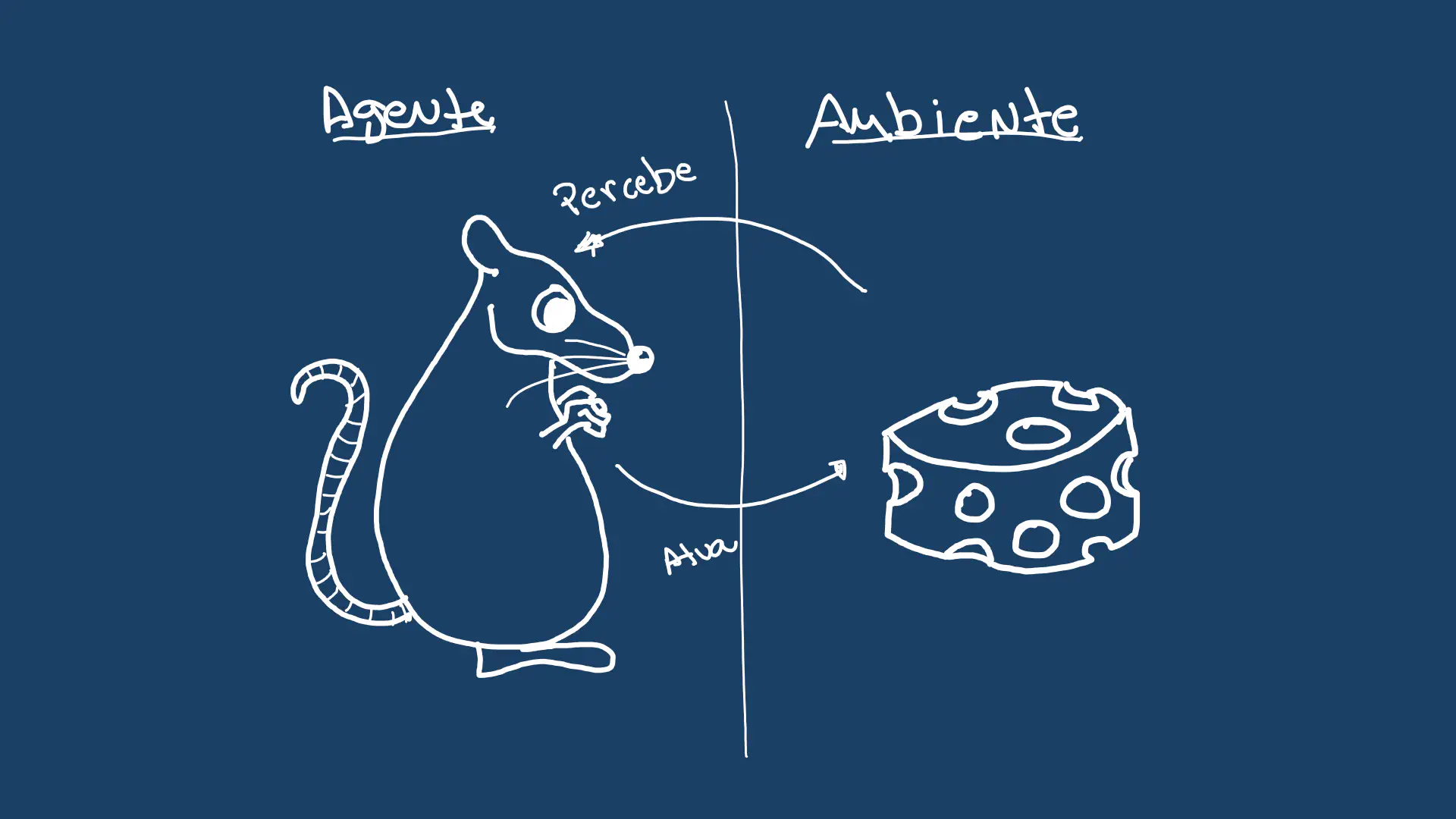
Um exemplo clássico são os agentes que aprendem a jogar videogame. O ambiente é o jogo. Os atuadores são os botões do controle. O agente observa a tela e muda o estado do jogo com suas ações. Essa definição continua válida na era da IA Generativa. Hoje temos sistemas que observam por imagem, texto ou áudio, e executam operações usando ferramentas.
A Anthropic popularizou outro conceito útil: os Agentic Workflows2. Pense neles como sequências de passos que usam LLMs e ferramentas, mas não controlam seu loop de execução.
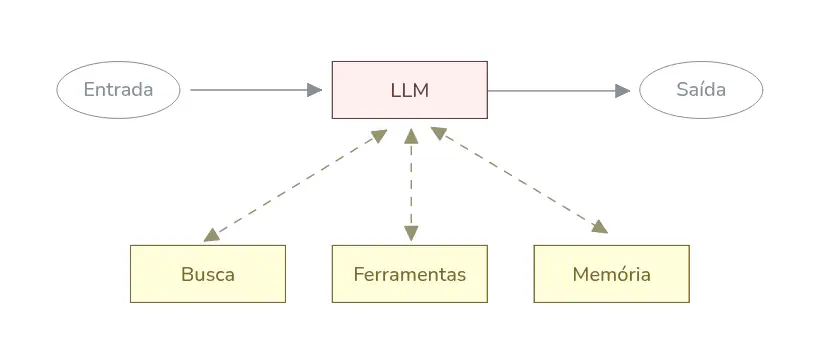
No fim, tanto agentes quanto workflows são compostos pelos mesmos blocos básicos: LLMs ampliadas. LLMs ampliadas podem buscar fontes externas de informações (RAG), executar ferramentas, ler e atualizar a memória. Em situações reais, um agente costuma ser uma composição de subagentes e sub-workflows montados a partir desses blocos.
Domando a complexidade
Se LLMs fossem perfeitas, bastaria escrever um megaprompt (do tamanho de um livro), conectar todas as ferramentas e soltar o agente no mundo. Na vida real, conforme o prompt e a lista de ferramentas aumenta, crescem também as confusões e alucinações.
Um estudo feito por Greg Kamradt avaliou a dificuldade dos modelos em achar uma informação relevante conforme o contexto aumenta (“agulha no palheiro”). O gráfico abaixo mostra este efeito no GPT-4: quanto maior o contexto (eixo x), pior a precisão para conteúdos no começo do prompt (eixo y).

Um bom processo de desenvolvimento leva este fator em conta, fragmentando a complexidade sempre que necessário, em um processo iterativo.
Agentes são grafos
Todo agente começa como um bloco de LLM ampliado. Um prompt, uma base de conhecimento, ferramentas e memória. Esse bloco pode ser visto como um vértice (nó) em um grafo direcionado. Esse vértice vai levar nosso agente até certo ponto. Conforme adicionamos novas instruções, casos de contorno e ferramentas, a tendência é que a performance se degrade. Chega um momento em que precisamos dividir.
flowchart TD n6["Entrada"] --> A A(["LLM Ampliado"]) A --> n7["Saída"] A:::llm n6:::io n7:::io classDef llm fill:#fff0f0, stroke:#643f3f, color:#643f3f classDef io stroke:#424242, fill:#FFFFFF, color:#424242
Na imagem acima temos um Agente de atendimento ao cliente. Ele tem um prompt detalhando com os diferentes casos de atendimento, bem como algumas ferramentas para atuar no ambiente. Em determinado momento, o esforço de evoluir este prompt fica grande e o retorno baixo. O agente começa a se confundir e a chamar a ferramenta errada nos momentos errados.
A solução? Separar um fluxo específico para este caso e introduzir um roteador. Agora, além do novo fluxo temos um nó que decide, a cada mensagem, qual caminho seguir.
flowchart TD n3["Entrada"] --> A A(["Roteador"]) --> n1(["Dúvida"]) & n2(["Mudança de endereço"]) n1 --> n4["Saída"] n2 --> n4 A:::llm n1:::llm n2:::llm n3:::io n4:::io classDef llm fill:#fff0f0, stroke:#643f3f, color:#643f3f classDef io stroke:#424242, fill:#FFFFFF, color:#424242
Repita esse processo sempre que a complexidade de um nó começar a prejudicar a acurácia. Em alguns casos, uma tarefa pode ser decomposta em um workflow com várias etapas. Um exemplo é quando um cliente envia uma imagem como evidência. O agente poderia ter um nó para validar a imagem e outro para concluir a avaliação com uma mensagem.
Como os prompts ficam mais focados e os nós contém apenas as ferramentas necessárias para execução das tarefas, a tendência é que a tarefa fique mais simples e o agente mais confiável.
flowchart TD n6["Entrada"] --> A A(["Roteador"]) --> n1(["Dúvida"]) & n2(["Mudança de endereço"]) & n3(["Problema com pedido (análise da imagem)"]) n3 --> n5(["Resposta final"]) n1 --> n7["Saída"] n2 --> n7 n5 --> n7 A:::llm n1:::llm n2:::llm n3:::llm n5:::llm n6:::io n7:::io classDef llm fill:#fff0f0, stroke:#643f3f, color:#643f3f classDef io stroke:#424242, fill:#FFFFFF, color:#424242
Existem várias formas de estruturar esta arquitetura. Devo colocar várias etapas dentro de um nó, ou apenas uma chamada de LLM? Não existe uma solução única, mas existem algumas ferramentas para nos guiar: rastreio (tracing), monitoramento e avaliação.
Vários frameworks tem integrações com ferramentas de rastreio e monitoramento. Essas integrações podem estar atreladas a chamadas de API ou ao vértice em si. Teste na sua stack para ver a granularidade que faz sentido para sua aplicação. Outro fator importante para decidir o melhor momento de fragmentar seu agente é a acurácia.
Quando decompor um nó: avaliação
A melhor bússola para decidir quando quebrar um nó é a avaliação. Sistemas de IA Generativa, assim como modelos discriminativos, precisam de uma avaliação bem estruturada para guiar decisões e acelerar o desenvolvimento. Neste contexto, considero avaliação a utilização de um conjunto de exemplos para mensurar a efetividade do agente.
Desta forma, quanto mais complexos os nós, mais casos de teste você deveria acumular. Afinal de contas, o agente precisa resolver um conjunto cada vez mais diverso de cenários e condições de contorno. O nó passa a ter tantas responsabilidades que fica cada vez mais difícil manter a acurácia na base de testes.
Neste momento você separa as responsabilidades entre nós para que seja mais fácil avaliar e evoluir os diferentes sub-sistemas. A avaliação na base de exemplos também acelera o desenvolvimento evitando regressões e novos bugs.
Fazer uma avaliação é simples quando a saída é “fechada” e exata. Por exemplo: para avaliar um nó que classifica sentimento (positivo, negativo, neutro). Basta usar métricas clássicas como precisão, revocação (recall) e acurácia. Porém como avaliar quando a saída é um parágrafo de texto?
LLM como juiz
Quando a saída é aberta, uma prática comum é usar uma LLM como juiz.Você pede para que a LLM avalie se a resposta gerada é semanticamente similar à resposta “ideal” do conjunto de avaliação.
Outro método é pedir para que a LLM avalie um critério específico da interação ou resposta. Por exemplo, se o problema foi resolvido com sucesso, se o tom de voz segue determinado critério ou se a mensagem demostrou empatia no atendimento.
Uma forma prática de refinar estes juízes é utilizando a biblioteca DSPy que permite evoluir a avaliação a partir de exemplos, sem precisar escrever prompts para isso.
Conclusões
No mundo ideal agentes seriam só prompt, base de conhecimento e uma longa lista de ferramentas. Porém, na prática, estes sistemas tendem a perder desempenho com a complexidade.
Uma abstração para evoluir agentes e administrar essa complexidade é o grafo. Vértices executam operações com LLMs e podem ser decompostos em sub-fluxos conforme necessário. Esse modelo acelera o desenvolvimento enquanto aumenta a qualidade do produto. É uma ótima forma de começar simples, iterar rápido e adicionar complexidade somente quando necessário.
Algumas bibliotecas seguem essa abstração, como o LangGraph e o CrewAI Flow (baseado em eventos, mas pode ser visto como um grafo implícito). Mesmo que sua biblioteca favorita não tenha um grafo, pensar agentes desta forma simplifica muito o processo.
-
Artificial Intelligence: A Modern Approach, Stuart Russell e Peter Norvig ↩︎